The First Breakthrough: e1
In the first half of 2025, with e1, we presented the first functional breakthrough of our new foundational architecture for Cognitive Reasoning. For the first time, we extended a language model with a cognitive control component to form what we call a “Cognitive System.” Even e1 impressively demonstrated that deductive reasoning and reconstructible argumentation paths can be mastered within the scope of machine text processing and generation—a pioneering step towards controllable, explainable, and simultaneously high-performance AI.
What is Cognitive Reasoning?
Cognitive Reasoning is a fundamentally new architectural approach for high-performance and simultaneously controllable AI systems. This architecture combines the expressive power and semantic diversity of large language models (LLMs) with a formal control unit: the Cognitive Control Unit (CCU). The CCU structures and directs thought processes based on so-called Cognitive Schemata and auditable logic artifacts (axioms). Thus, the CCU determines how thoughts are formed, not just what is said. This creates traceable, explicit thought paths that give the overall process structure and control without curtailing the actual intelligence.
For a detailed description of the architecture, we refer to our technical article:
“Cognitive Reasoning – an innovative foundational architecture for controllable, structured AI systems.“
The goal of this present e2-research#1 publication is to provide initial answers to the question: how far can this architecture take us?
Following the promising results of e1, the central question quickly arose: can the (benchmark) performance be further increased—and can this be done solely through the optimization of the cognitive architecture (i.e., without resource-intensive and time-consuming training)? We have dedicated ourselves to this question within the scope of this publication.
The following analyses (e2-research#1) are based on initial studies that we conducted over a two-week period in the second half of June 2025 in search of answers to the aforementioned question. The underlying language models remained unchanged in all analyses; only the architecture of the CCU (more specifically: the Cognitive Schemata used) was modified—with the aim of making the thought structure even more efficient, consistent, and adaptive.
For reasons of speed and validation, the analyses presented below were conducted in parallel with two different base models: an open-weight Llama 3.3 70B and the closed-weight GPT-4.1-mini. For the upcoming publication (e2-research#2), both benchmarks will also be performed with additional base models.
Analysis Dimension 1: Logical Puzzles with Semantic Components (HardReasoning-DE)
The HardReasoning-DE benchmark tests AI systems with challenging logical puzzles that go far beyond simple conclusions. The tasks combine structured logic with complex semantic contexts—for example, analyzing sports team strategies over several games or optimizing project resources under sustainability constraints.
These challenges require not only logical thinking but also the ability to understand semantic constraints, set priorities, and develop consistent solution paths in combination with the logical requirements. This combination of logic and semantics is less common in the training data of language and reasoning models than pure logic puzzles; therefore, the ability for dynamic, complex reasoning (as opposed to the mere reproduction of pre-trained language patterns) plays a particularly significant role here.
Analysis Dimension 1: Logical Puzzles with Semantic Components (HardReasoning-DE)
The HardReasoning-DE benchmark tests AI systems with challenging logical puzzles that go far beyond simple conclusions. The tasks combine structured logic with complex semantic contexts—for example, analyzing sports team strategies over several games or optimizing project resources under sustainability constraints.
These challenges require not only logical thinking but also the ability to understand semantic constraints, set priorities, and develop consistent solution paths in combination with the logical requirements. This combination of logic and semantics is less common in the training data of language and reasoning models than pure logic puzzles; therefore, the ability for dynamic, complex reasoning (as opposed to the mere reproduction of pre-trained language patterns) plays a particularly significant role here.
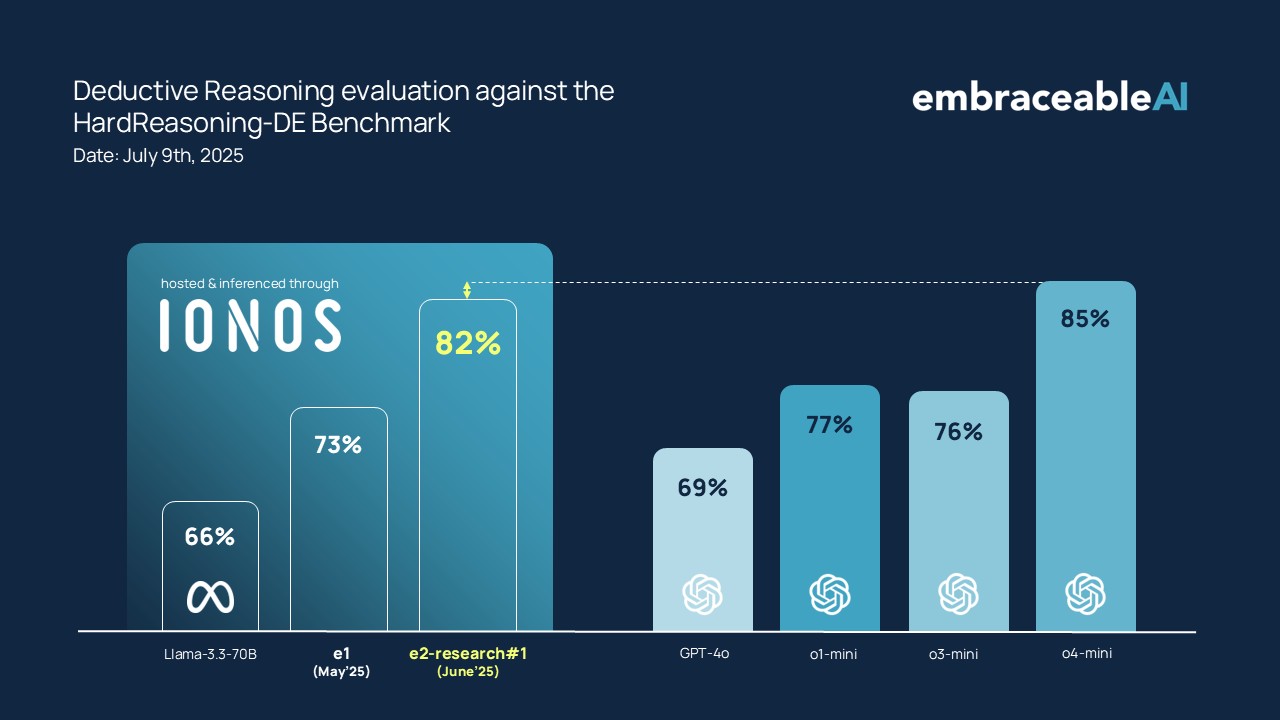
HardReasoning-DE Results:
e2 shows a significant performance leap compared to e1 in correctly solving the puzzles. Both systems use a medium-sized Llama 3.3 70B as a hypothesis generator and validator for this benchmark.
Even in this setup, e2 surpasses leading reasoning models like o3-mini and is only narrowly beaten by o4-mini.
Analysis Dimension 2: Purely Logical Puzzles with High Logical Depth (ZebraLogicBench)
To evaluate primarily logical performance, we use the established benchmark ZebraLogicBench from AllenAI (Ai2) & Stanford University, which investigates the scaling limits of LLMs in logical reasoning. The benchmark measures the ability of models to maintain consistent thinking operations even across multiple deductive steps—an ideal reference for our goal.
These tasks follow the same principle as the famous Einstein Riddle (also known as the “Zebra Puzzle”), where people with different characteristics are assigned to different houses. For illustrative purposes, this Einstein Riddle is shown below:

For the initial analyses in the context of the e2-research#1 investigation, we limited ourselves to the XL variants of the Zebra benchmark for time reasons. These XL variants are particularly challenging as they require a larger number of variables and constraints, as well as significantly longer chains of logical conclusions. The processing time for humans is typically between 30 and 45 minutes. The XL puzzles range in complexity from 4 houses with 6 attributes to the most difficult puzzles with a 6×6 matrix.
For our evaluation, we translated the puzzles of the ZebraLogicBench into German to ensure correct linguistic reference.
The initial analysis results are presented in the following table:
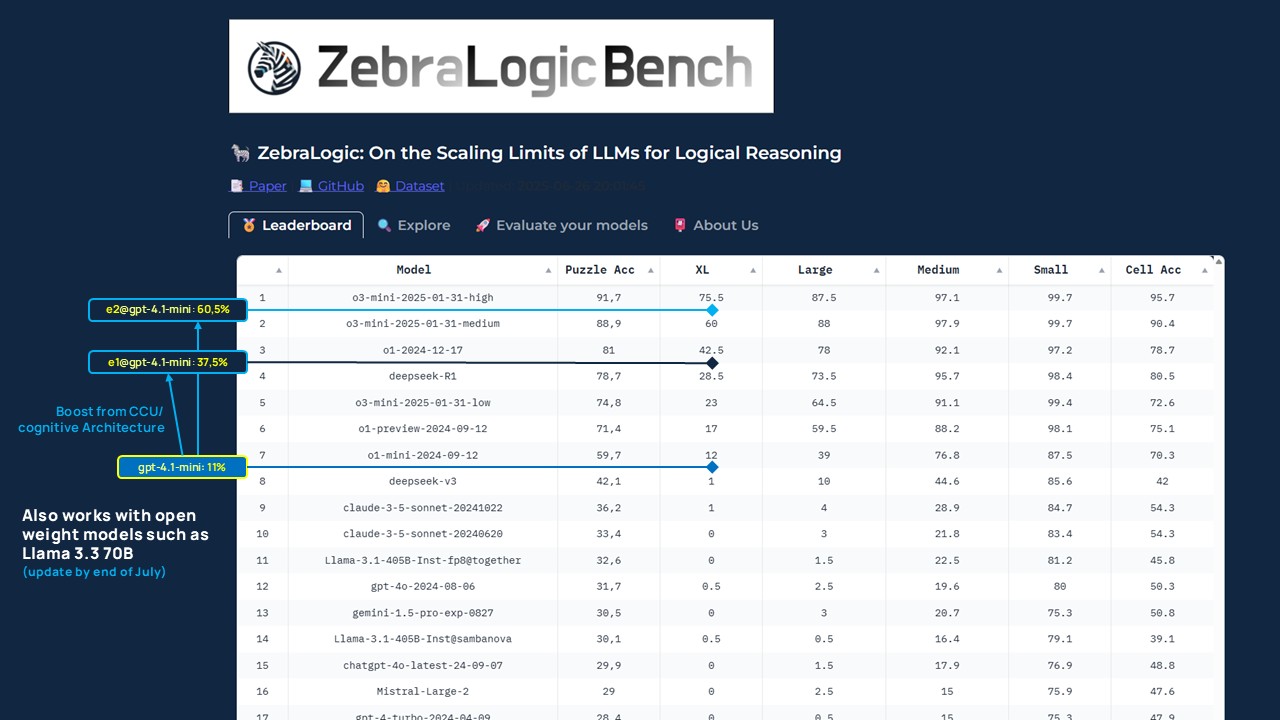
ZebraLogicBench Results: The Influence of Cognitive Architecture
The initial analysis results impressively show a) the influence and b) the progress of the cognitive architecture: While [email protected] achieves 4th place in the benchmark, [email protected], with its stronger ‘Cognitive Schema,’ is currently positioned at 2nd place in the rankings (as of July 10, 2025). This significant improvement was achieved without any changes to the underlying language model—solely through the systematic further development of the CCU architecture (specifically, the ‘Cognitive Schema’).
In direct comparison, the performance gains are clearly visible:
- The base model (gpt-4.1-mini) achieves an XL-Puzzle Accuracy of 11% without a cognitive architecture.
- With the first iteration of the cognitive architecture ([email protected]), performance increases to 37.5%—solely through the embedding of the CCU and structured validation.
- With [email protected] (as of July 10, 2025), a value of ~60.5% is achieved with otherwise identical parameters.
This increase was achieved without larger models and without additional training, but exclusively through architectural innovation. It indicates just how great the potential of Cognitive Systems truly is.
Summary and outlook
Cognitive Reasoning shines not only in purely logical reasoning performance (see Zebra benchmark) but especially in the combination of logic and semantic interpretation (see Hard Reasoning benchmark). It is precisely this combination that is crucial in many of our use cases when it comes to sophisticated Decision- & Action-AI where a reliable interpretation of rules & regulations is essential.
Besides the absolute performance, the progress from e1 to e2-research#1 is particularly noteworthy: our cognitive architecture enables performance leaps that are not achievable with classic model scaling in this form. All improvements were achieved without additional training, but exclusively through the optimization of the cognitive architecture. The performance gains achieved give an outline of how great the potential of Cognitive Systems truly is.
Although further analyses are pending, these results point in a clear direction: through the orchestration of thought patterns, structured context composition, and step-by-step validation, LLMs can be further developed into Cognitive Systems that act traceably and consistently while maintaining high performance. These are very clear and encouraging signals.
However, we are only at the beginning of this journey towards cognitive system architectures. The question we now ask ourselves is: how far can (and will) this foundational innovation take us?
We are increasingly coming to the conviction that cognitive architectures are not just isolated improvements, but possibly a fundamentally new scaling path for a new generation of trustworthy, high-performance, and explainable AI systems—and we look forward to exploring this path with determination through even more consistent and intensive research & development.
We will communicate new updates at the end of July 2025.
Referencen und Sources
Hard-Reasoning-DE Benchmark: https://huggingface.co/datasets/embraceableAI/HARD-REASONING-DE
ZebraLogicBench: https://huggingface.co/spaces/allenai/ZebraLogic
ZebraLogic: On the Scaling Limits of LLMs for Logical Reasoning: https://arxiv.org/pdf/2502.01100
ZebraLogic Dataset: https://huggingface.co/datasets/WildEval/ZebraLogic
Zebra-Logic Matrix Complexity: https://github.com/WildEval/ZeroEval/blob/main/zebra_logic_analysis/heatmap_size.png
{kind=link}
