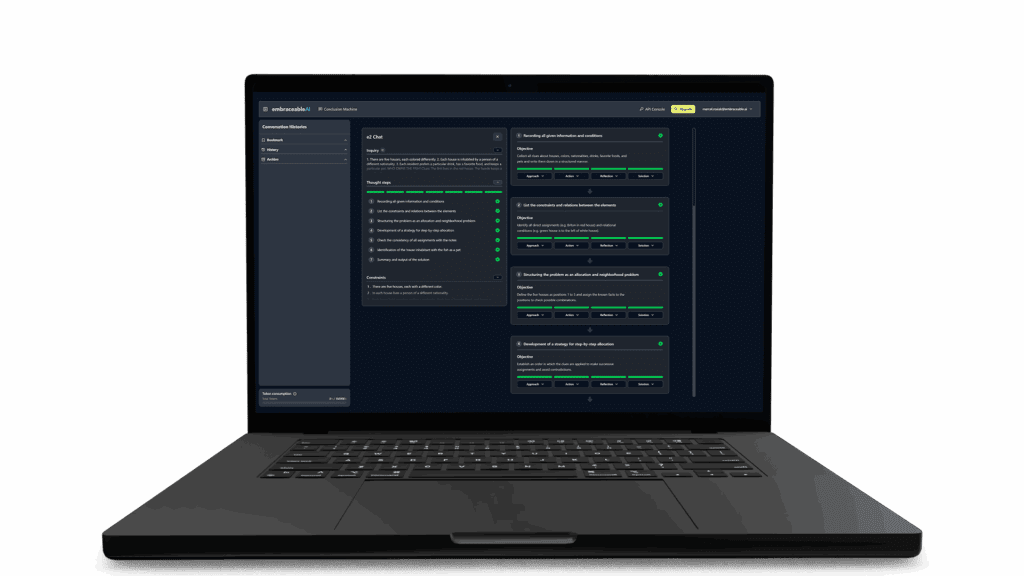
Evaluate and resolve this case while complying with all Policies.
What is this example about?
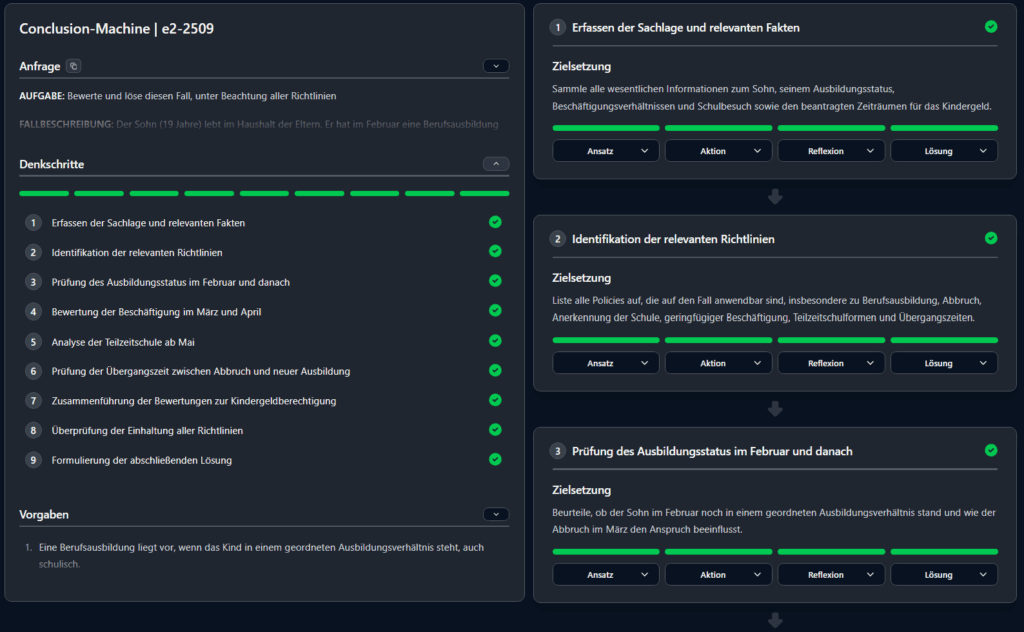
It is about correctly solving a given task while observing normative constraints—i.e., regulations and rules. In this scenario, the system supports a public agency by performing a legal pre-assessment for a child benefit application. This requires step-by-step derivation, meaning real “cognitive work”.
The task demands a precise verification of entitlement periods against a complex policy logic specifically analyzing the transition phase between high school and university. A single false logical step—e.g., overlooking a 4-month deadline—leads to an incorrect notification of decision.
Important Disclaimer: This example is illustrative
The case described here and the subsequent explanations serve to illustrate the working method of CCMs. However, the functional principle of CCMs is in no way limited to “Child Benefit.”
CCMs operate domain-agnostically.
On the contrary: CCMs “think” across domains based on general world knowledge and universally valid deductive reasoning. However, individual, organization-specific knowledge can easily be connected as an external source—without the need for extensive training. If you already possess individually trained LLMs, we can integrate them precisely.
Contact our Solution Team, if you would like to know more about the different integration scenarios.
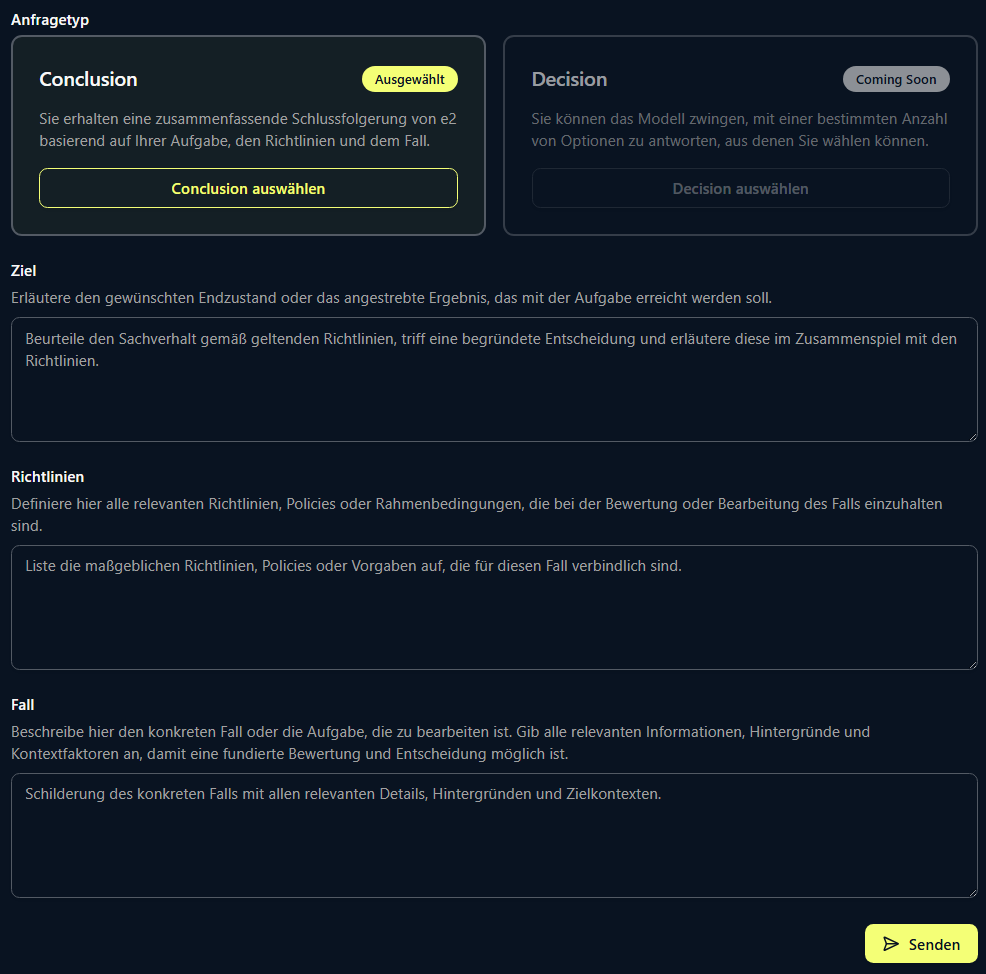
For standardized operations, you naturally do not enter these Policies manually. CCMs are designed to integrate seamlessly into your existing knowledge architecture. Policies and facts (the “context”) are dynamically injected into the model:
Safety First:If the CCM determines that the available information or rules lead to a contradiction, it aborts the process in a controlled manner or requests clarification. The principle is: Better no answer than a hallucinated, incorrect answer.
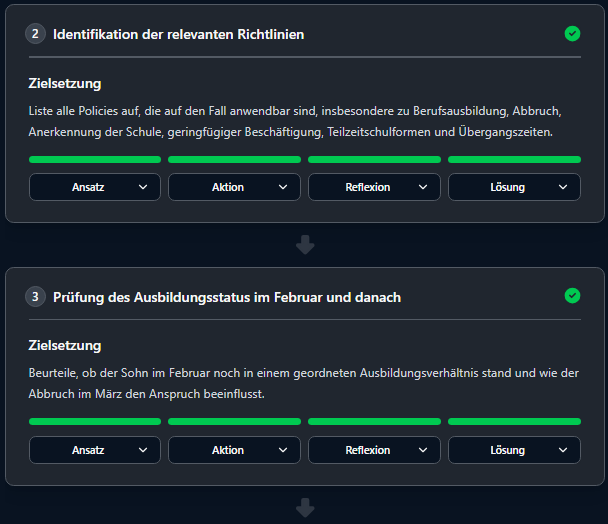
Fact Extraction: What data is available for the period?
Rule Application: Does POL-106 (transition period) apply in this specific month?
Interim Conclusion: Status determined for subsection X.
Validation: Does this step violate a policy? -> Block.
Verification: Is the logical derivation valid? -> Accept.
This linear, causal sequence prevents getting “lost” in the token space, which often leads to unstable results with standard LLMs.
This continuous self-monitoring (Self-Correction) ensures that errors do not propagate through the chain. The result is a drastically reduced hallucination rate.
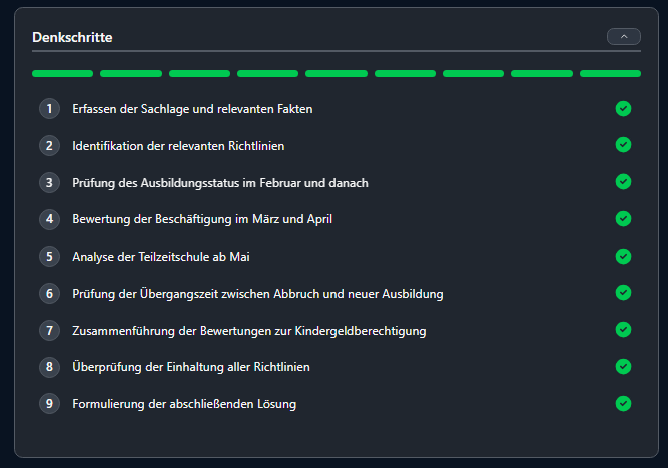
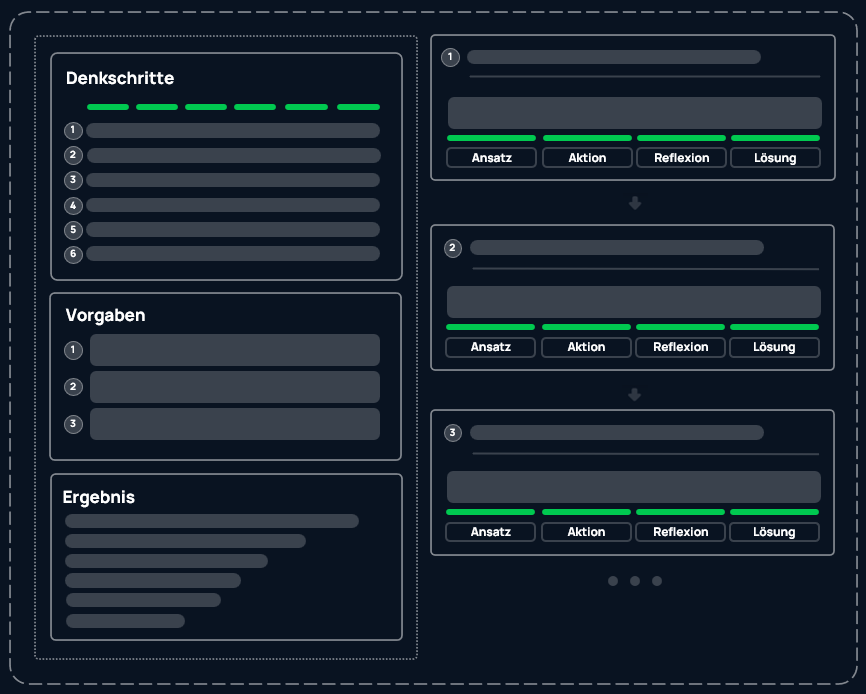
The solution does not emerge from a “Black Box.” The CCM decomposes the complex problem into atomic, logical units. Each step builds upon the previous one:
Fact Extraction: What data is available for the period?
Rule Application: Does POL-106 (transition period) apply in this specific month?
Interim Conclusion: Status determined for subsection X.
Validation: Does this step violate a policy? -> Block.
Verification: Is the logical derivation valid? -> Accept.
This linear, causal sequence prevents getting “lost” in the token space, which often leads to unstable results with standard LLMs.
This continuous self-monitoring (Self-Correction) ensures that errors do not propagate through the chain. The result is a drastically reduced hallucination rate.
In the end, you receive not only the result of the reasoning chain (including justifications) but the complete Audit Trail. You can trace exactly why the model decided as it did:
Which policy did it reference?
Which fact was decisive?
What was the logical chain?
This level of transparency and granularity makes AI decisions audit-proof and traceable—a must for regulated industries.
LLMs are fantastic tools for creativity and assistance. But when it comes to robust conclusions in mission-critical business processes, high stochastic ambiguity within long chains of thought becomes an undesirable or even unacceptable risk.
CCMs address this “Skill Gap”: enabling conclusions that correspond to real cognitive work at the level of human experts—meaning with high precision, adherence to rules, and traceable justifications.
You can now view the case shown above in its entirety, including every detail regarding derivations and justifications. No account or login is required. Simply click the link to start your journey of discovery.
Alternatively, you can create a free account for the Conclusion UI and take your first steps in a sandbox environment using your own case example.
If you need support, we are always here to help.
Unsere Conclusion Models bewähren sich bereits in einer Vielzahl produktiver Anwendungsfälle, bei denen es allesamt auf hochwertige und strukturierte Schlussfolgerungen mit entsprechender Transparenz und Nachvollziehbarkeit ankommt. Die nachfolgenden Beispiele zeigen einen Querschnitt über unterschiedliche Fachgebiete und Prozess-Gruppen im Unternehmen im Rahmen automatisierter Fall-Vorverarbeitung.
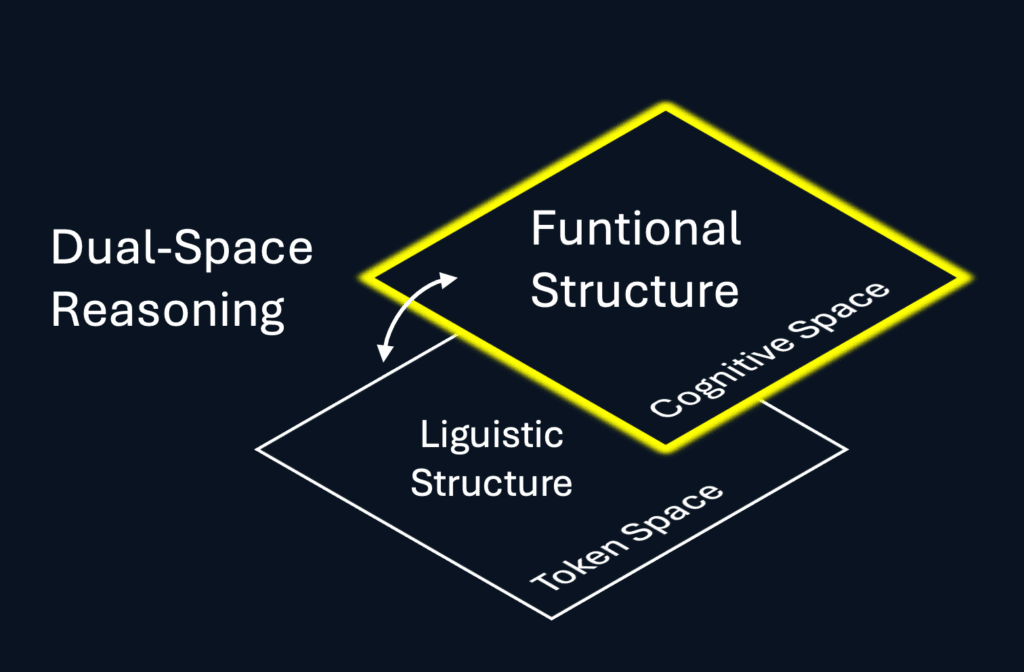
CCMs are not merely “better LLMs,” as they possess a distinct, secondary representation space.
Reasoning within the linguistic space is structurally limited: the longer the chains of thought, the more unstable the results tend to become.
The explicit reasoning architecture of CCMs enables the structuring and stabilization of long chains of thought, thereby increasing the quality of conclusions—especially when normative requirements and regulations must be observed.