Der erste Durchstich: e1
In der ersten Jahreshälfte 2025 haben wir mit e1 den ersten funktionalen Durchstich unserer neuen Basis-Architektur für Kognitives Reasoning präsentiert. Dafür haben wir erstmals ein Sprachmodell mit einer kognitiven Steuerungskomponente zu einem so genannten „Kognitiven System“ erweitert. Bereits e1 zeigte eindrucksvoll, dass deduktives Denken und rekonstruierbare Argumentationspfade auch im Rahmen maschineller Textverarbeitung und -Generierung beherrschbar werden – ein wegweisender Schritt in Richtung steuerbarer, erklärbarer und gleichzeitig leistungsstarker KI.
Was ist Kognitives Reasoning?
Bei Kognitivem Reasoning handelt es sich um einen grundlegend neuen Architektur-Ansatz für leistungsstarke und gleichzeitig steuerbare KI-Systeme. Diese Architektur verbindet die Ausdrucksstärke und semantische Vielfalt großer Sprachmodelle (LLMs) mit einer formalen Kontrolleinheit: der Cognitive Control Unit (CCU). Die CCU strukturiert und dirigiert Denkprozesse auf Basis so genannter Cognitive Schemata sowie auditierbarer Logikartefakte (Axiome). Die CCU bestimmt also, wie gedacht wird, nicht nur, was gesagt wird. Auf diese Weise entstehen nachvollziehbare, explizite Denkpfade, die dem Gesamtprozess Struktur und Kontrolle geben, ohne die eigentliche Intelligenz zu beschneiden.
Für eine detaillierte Beschreibung der Architektur verweisen wir auf unseren Fachartikel:
„Kognitives Reasoning – eine innovative Basis-Architektur für steuerbare, strukturierte KI-Systeme“.
Ziel dieser vorliegenden e2-research#1 Veröffentlichung sind erste Antworten auf die Frage: wie weit trägt die Architektur?
Nach den vielversprechenden Ergebnissen von e1 stand schnell die zentrale Frage im Raum: lässt sich die (Benchmark-)Performance noch weiter steigern – und zwar allein durch Optimierung der kognitiven Architektur (also ohne ressourcenintensives und zeitaufwändiges Training)? Dieser Frage haben wir uns im Rahmen der vorliegenden Veröffentlichung gewidmet.
Die nachfolgenden Ausführungen (e2-research#1) basieren auf ersten Analysen, die wir auf der Suche nach Antworten auf die o.g. Frage in einem Zeitraum von 2 Wochen in der zweiten Juni-Hälfte 2025 durchgeführt haben. Die zugrunde liegenden Sprachmodelle blieben bei allen Analysen unverändert; modifiziert wurde ausschließlich die Architektur der CCU (genauer gesagt: die verwendeten Cognitive Schemata) – mit dem Ziel, die Denkstruktur noch effizienter, konsistenter und adaptiver zu gestalten.
Aus Gründen der Geschwindigkeit und der Validierung wurden die nachfolgend dargestellten Analysen mit zwei unterschiedlichen Basis-Modellen parallel durchgeführt: einem Open Weight Llama 3.3 70B und dem Closed Weight GPT-4.1-mini. Für die kommende Veröffentlichung (e2-research#2) werden beide Benchmarks auch mit weiteren Basis-Modellen durchgeführt.
Analyse-Dimension 1: Logische Puzzles mit semantischen Anteilen (HardReasoning-DE)
Der HardReasoning-DE Benchmark prüft KI-Systeme mit anspruchsvollen logischen Rätseln, die weit über einfache Schlussfolgerungen hinausgehen. Die Aufgaben kombinieren strukturierte Logik mit komplexen semantischen Kontexten – beispielsweise die Analyse von Sportteam-Strategien über mehrere Spiele hinweg oder die Optimierung von Projektressourcen unter Nachhaltigkeitsvorgaben.
Diese Herausforderungen erfordern nicht nur logisches Denken, sondern auch die Fähigkeit, semantische Einschränkungen zu verstehen, Prioritäten zu setzen und in Kombination mit den logischen Vorgaben konsistente Lösungswege zu entwickeln. Diese Kombination aus Logik & Semantik ist in den Trainingsdaten von Sprach- und Reasoning-Modellen seltener zu finden als reine Logik-Rätsel; daher spielt die Fähigkeit für dynamische, komplexe Schlussfolgerungen (ggü. der reinen Reproduktion vortrainierter Sprachmuster) hier eine besonders große Rolle.
Analyse-Dimension 1: Logische Puzzles mit semantischen Anteilen (HardReasoning-DE)
Der HardReasoning-DE Benchmark prüft KI-Systeme mit anspruchsvollen logischen Rätseln, die weit über einfache Schlussfolgerungen hinausgehen. Die Aufgaben kombinieren strukturierte Logik mit komplexen semantischen Kontexten – beispielsweise die Analyse von Sportteam-Strategien über mehrere Spiele hinweg oder die Optimierung von Projektressourcen unter Nachhaltigkeitsvorgaben.
Diese Herausforderungen erfordern nicht nur logisches Denken, sondern auch die Fähigkeit, semantische Einschränkungen zu verstehen, Prioritäten zu setzen und in Kombination mit den logischen Vorgaben konsistente Lösungswege zu entwickeln. Während herkömmliche Sprach- und Reasoning-Modelle bei solchen Aufgaben oft inkonsistent werden, zeigt unsere kognitive Architektur durch strukturierte Denkprozesse deutlich nachvollziehbarere Ergebnisse.
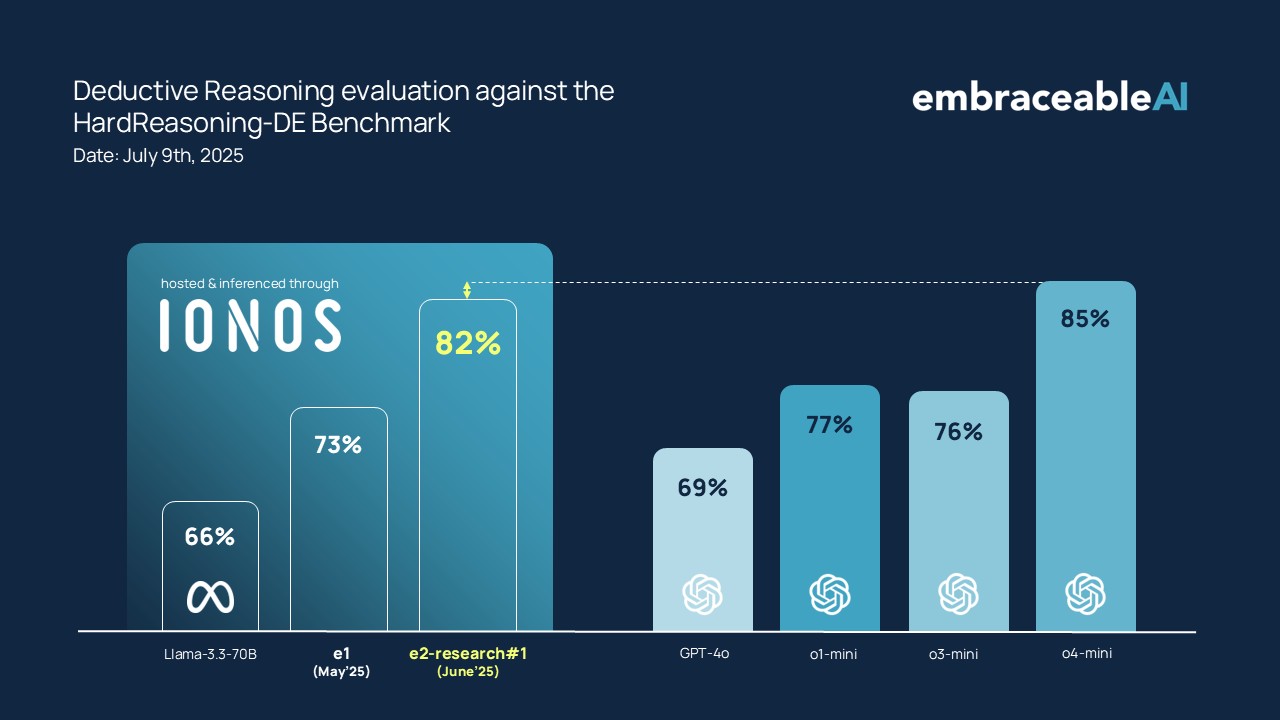
Ergebnisse HardReasoning-DE:
e2 zeigt ggü. e1 einen deutlichen Leistungssprung in der korrekten Lösung der Rätsel. Beide Systeme nutzen für diesen Benchmark ein mittelgroßes Llama 3.3 70B als Hypothesen-Generator und -Validator.
Bereits in diesem Setup überholt e2 führende Reasoning-Modelle wie o3-mini und muss sich lediglich o4-mini knapp geschlagen geben.
Analyse-Dimension 2: rein Logische Puzzles mit hoher Logik-Tiefe (ZebraLogicBench)
Zur Evaluation der primär logischen Performance nutzen wir den etablierten Benchmark ZebraLogicBench von allenAI (Ai2) & Stanford University, der die Skalierungsgrenzen von LLMs im logischen Reasoning untersucht. Der Benchmark misst die Fähigkeit von Modellen, konsistente Denkoperationen auch über mehrere deduktive Schritte hinweg aufrechtzuerhalten – eine ideale Referenz für unser Ziel.
Diese Aufgaben folgen dem gleichen Prinzip wie das bekannte Einstein-Rätsel (auch „Zebra-Puzzle“ genannt), bei dem Personen mit unterschiedlichen Eigenschaften verschiedenen Häusern zugeordnet werden. Zu Illustrationszwecken ist dieses Einstein-Rätsel nachfolgend dargestellt:

Für die erste Analysen im Rahmen der e2-research#1 Untersuchung haben wir uns aus Zeitgründen auf die XL-Varianten des Zebra Benchmarks beschränkt. Diese XL-Varianten sind besonders anspruchsvoll, da sie eine größere Zahl an Variablen und Einschränkungen sowie deutlich längere Ketten logischer Schlussfolgerungen erfordern. Die Bearbeitungszeit für Menschen liegt typischerweise bei 30 bis 45 Minuten. Die XL-Puzzle reichen von einer Komplexität von 4 Häusern mit 6 Eigenschaften bis zu den schwierigsten Rätseln mit einer Matrix von 6×6.
Für unsere Evaluation haben wir die Puzzles des ZebraLogicBench ins Deutsche übersetzt, um die korrekte sprachliche Referenz zu gewährleisten.
Die ersten Analyse-Ergebnisse sind in nachfolgender Tabelle dargestellt:
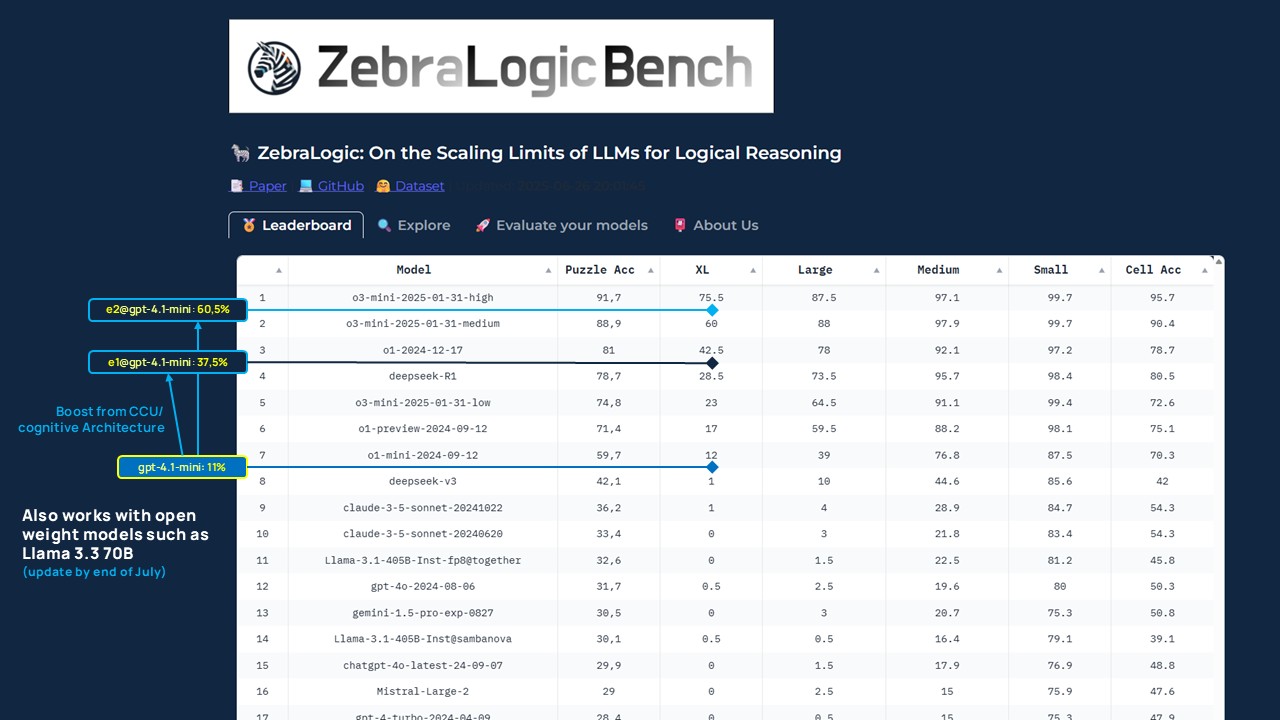
Ergebnisse ZebraLogicBench: der Einfluss der kognitiven Architektur
Die ersten Analyse-Ergebnisse zeigen eindrucksvoll a) den Einfluss und b) den Fortschritt der kognitiven Architektur: Während [email protected] Platz 4 im Benchmark erreicht, positioniert sich [email protected] mit seinem stärkeren ‚Cognitive Schema‘ aktuell auf Platz 2 der Rangliste (Stand 10.07.2025). Diese signifikante Verbesserung wurde ohne jegliche Veränderung am darunterliegenden Sprachmodell erzielt – allein durch die systematische Weiterentwicklung der CCU-Architektur (konkret: des ‚Cognitive Schema‘).
Im direkten Vergleich zeigen sich die Leistungszuwächse deutlich:
- das Basismodell (gpt-4.1-mini) erreicht ohne kognitive Architektur eine XL-Puzzle Accuracy von 11 %.
- mit der ersten Iteration der kognitiven Architektur ([email protected]) steigt die Performance auf 37,5 % – allein durch die Einbettung der CCU und strukturierte Validierung.
- mit [email protected] (Stand 10.07.2025) wird, bei ansonsten identischen Parametern, ein Wert von ~60,5 % erreicht.
Diese Steigerung wurde ohne größere Modelle und ohne zusätzliches Training erzielt, sondern ausschließlich durch architektonische Innovation. Sie deutet an, wie groß das Potenzial von Cognitive Systems tatsächlich ist.
Zusammenfassung und Ausblick
Kognitives Reasoning glänzt nicht nur bei der rein logischen Reasoning-Performance (s. Zebra Benchmark), sondern insbesondere bei der Kombination aus Logik und semantischer Interpretation (s. Hard Reasoning Benchmark). Gerade diese Kombination ist in vielen unserer Use-Cases ausschlaggebend, wenn es um anspruchsvolle Entscheidungs- & Handlungs-KI geht und es dabei auf eine verlässliche Interpretation von Regeln & Vorschriften ankommt.
Neben der absoluten Performance sind insbesondere die Fortschritte von e1 auf e2-research#1 bemerkenswert: unsere kognitive Architektur ermöglicht Leistungssprünge, die mit klassischer Modellskalierung in dieser Form nicht zu erreichen sind. Sämtliche Verbesserungen wurden ohne zusätzliches Training erzielt, sondern ausschließlich durch Optimierung der kognitiven Architektur. Die erreichten Leistungssprünge deuten in Umrissen an, wie groß das Potenzial Kognitiver Systeme tatsächlich ist.
Auch wenn weitere Analysen ausstehen, zeigen diese Ergebnisse in eine eindeutige Richtung: durch Orchestrierung von Denkmustern, strukturierte Kontextkomposition und schrittweise Validierung lassen sich LLMs zu Kognitiven Systemen weiterentwickeln, die nachvollziehbar und konsistent agieren und gleichzeitig hohe Leistungsfähigkeit behalten. Das sind sehr eindeutige und ermutigende Signale.
Wir stehen jedoch erst am Anfang dieser Reise hin zu kognitiven System-Architekturen. Die Frage, die wir uns nun stellen, lautet: wie weit kann (und wird) uns diese Grundlagen-Innovation noch tragen?
Wir gelangen zunehmend zu der Überzeugung, dass kognitive Architekturen keine punktuellen Verbesserungen, sondern möglicherweise ein grundsätzlich neuer Skalierungspfad für eine neue Generation vertrauenswürdiger, leistungsfähiger und erklärbarer KI-Systeme ist – und wir freuen uns darauf, diesen Weg durch noch konsequentere und intensivere Forschung & Entwicklung zielstrebig zu erkunden.
Neue Updates werden wir Ende Juli 2025 kommunizieren.
Referenzen und Quellen
Hard-Reasoning-DE Benchmark: https://huggingface.co/datasets/embraceableAI/HARD-REASONING-DE
ZebraLogicBench: https://huggingface.co/spaces/allenai/ZebraLogic
ZebraLogic: On the Scaling Limits of LLMs for Logical Reasoning: https://arxiv.org/pdf/2502.01100
ZebraLogic Dataset: https://huggingface.co/datasets/WildEval/ZebraLogic
Zebra-Logic Matrix Complexity: https://github.com/WildEval/ZeroEval/blob/main/zebra_logic_analysis/heatmap_size.png
{kind=link}
