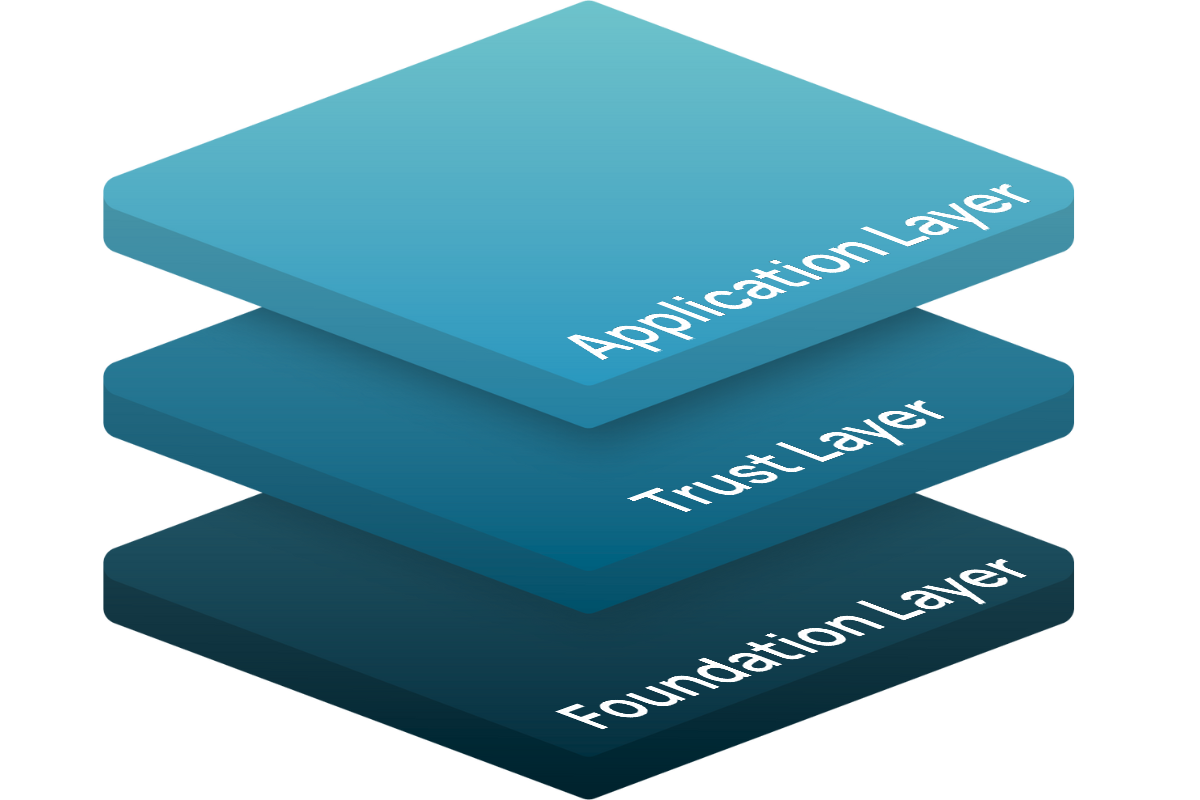
Im Application-Layer befindet sich die eigene Low-/No-Code Agentic Automation Plattform für die Nutzung & Konfiguration über die UI. Dort können sie konkrete Use-Cases & Anwendungen konfigurieren, in der UI erproben und per API für die Integration in Ihre Workflow-Tools auf Wunsch konsumierbar machen.
Der Trust-Layer des Stacks umfasst ein Enterprise-Grade Berechtigungs-Konzept, welches die im Foundation-Layer angelegten Objekte entsprechend verwalten & zuweisen lässt. Außerdem sind dort auch das Logging, Compliance-Gateways und unsere Conclusion Machines als Basis-Komponente verortet.
Der Stack baut direkt auf der Infrastruktur-Ebene auf mit Kubernetes & Object Storage auf und wird um PaaS-Bausteine ergänzt. Diese umfassen die Verarbeitung, Verwaltung & Konfiguration von eigenen Wissensdatenbanken, Anbindung von Drittsystemen und die Integration von Sprachmodellen.
Die Leistungsfähigkeit unserer aktuellen Conclusion Machine e2-2509 übertrifft sogar die führenden Reasoning Modelle von OpenAI, Anthropic & Co.
Der Skalierungspfad starker KI wird nicht länger über die Größe von Modellen (samt immensem Ressourcen-Einsatz für deren Training) bestimmt, sondern über die Leistungsfähigkeit kognitiver Architekturen in intelligenten Systemen.
Wir sehen uns als Vordenker und Vorreiter kognitiver Architekturen und erschaffen eigene IP auf Grundlagen-Ebene, um diesen Pfad aus eigener Kraft — d.h. ohne jegliche Abhängigkeiten von Dritten — zu beschreiten und mit zu prägen. Regulatorik sehen wir dabei nicht als Hindernis, sondern als Ansporn.
Wir verfügen über sämtliche Skills & Basis-Technologien, um Kognitive Intelligenz ohne jegliche Abhängigkeiten von Dritten zu entwickeln: unsere Cognitive Control Unit bildet das strukturelle Rückgrat, um aus rohen Gedanken von Sprachmodellen starke und kontrollierbare KI-Systeme zu machen. Grundsätzlich bevorzugen wir es, mit Standard-Modellen zu arbeiten. Gleichzeitig können wir bei Bedarf mit SynthIOS unsere eigenen, veredelten Trainingsdaten erzeugen und dank LoRA-Finetuning auf Open Weight Foundation Modelle anwenden.
Abgesehen von eigenen Foundation Modellen (für deren Training wir aufgrund der Verfügbarkeit hinreichend leistungsstarker Open Weight Modelle mit permissiven Lizenzen keine strategische Notwendigkeit sehen) besitzen wir damit alle wesentlichen Fähigkeiten und Werkzeuge, um Kognitives Intelligenz als globalen Skalierungspfad für Starke KI eigenständig voran zu treiben.
Um Denk- und Handlungs-KI strategisch kontrollierbar zu machen, haben wir ihre grundlegende Architektur neu gedacht — nicht in Modellen, sondern in Systemen. Dazu stellen wir Sprachmodellen mit unserer eigenständigen Cognitive Control Unit ein Denk-Zentrum an die Seite, welches die Hypothesen des Sprachmodells zerlegt, analysiert und überprüft. Im Ergebnis entstehen logisch nachvollziehbare und begründete Denkpfade.
Cognitive Memory ist der dynamische Arbeitsspeicher unserer Thinking- / Conclusion-Machines, der alle Denk-Artefakte zwischenspeichert und der Cognitive Control Unit zur Verfügung stellt. Dieser wird in Lang- & Kurzzeitspeicher unterteilt, der den zu verarbeitenden Kontext aktiv steuert, um die entsprechende Artefakte zu generieren und zu validieren. Diese Steuerung ermöglicht es, gezielt und strukturiert Zusammenhänge zu ziehen und zu erschließen.
Wahre Souveränität bedeutet, starke KI dort nutzen zu können, wo sie gebraucht wird – auch auf ressourcenschonender Low-End-Hardware. Wir forschen an Methoden, um anspruchsvolle KI-Modelle auf solchen „Low-Profile“-Umgebungen hocheffizient zu betreiben. Dies maximiert nicht nur Ihre Unabhängigkeit, sondern ermöglicht auch völlig neue Anwendungsfälle direkt am Ort des Geschehens.
Um Denk- und Handlungs-KI strategisch kontrollierbar zu machen, haben wir ihre grundlegende Architektur neu gedacht — nicht in Modellen, sondern in Systemen. Dazu stellen wir Sprachmodellen mit unserer eigenständigen Reasoning Engine einen Gegenspieler an die Seite, der die Hypothesen des Sprachmodells zerlegt, analysiert und überprüft. Im Ergebnis entstehen logisch nachvollziehbare und begründete Schlussfolgerungen, die als Grundlage belastbarer Entscheidungen dienen.
Die Qualität von Trainings-Daten hat einen maßgeblichen Einfluss auf das Verhalten von KI-Systemen. Statt uns auf externe Quellen zu verlassen, erzeugen wir mit unserer Open-Source-Pipeline SynthIOS unsere eigenen hochqualitativen Trainingsdaten. So stellen wir sicher, dass die hinterlegten Modelle auf der bestmöglichen und relevantesten Wissensbasis operieren und frei von unerwünschten Verzerrungen sind. Wir entwickeln unsere Daten-Pipelines kontinuierlich weiter.
Um Denk- und Handlungs-KI strategisch kontrollierbar zu machen, haben wir ihre grundlegende Architektur neu gedacht — nicht in Modellen, sondern in Systemen. Dazu stellen wir Sprachmodellen mit unserer eigenständigen Cognitive Control Unit ein Denk-Zentrum an die Seite, welches die Hypothesen des Sprachmodells zerlegt, analysiert und überprüft. Im Ergebnis entstehen logisch nachvollziehbare und begründete Denkpfade.
Cognitive Memory ist der dynamische Arbeitsspeicher unserer Thinking- / Conclusion-Machines, der alle Denk-Artefakte zwischenspeichert und der Cognitive Control Unit zur Verfügung stellt. Dieser wird in Lang- & Kurzzeitspeicher unterteilt, der den zu verarbeitenden Kontext aktiv steuert, um die entsprechende Artefakte zu generieren und zu validieren. Diese Steuerung ermöglicht es, gezielt und strukturiert Zusammenhänge zu ziehen und zu erschließen.
Wahre Souveränität bedeutet, starke KI dort nutzen zu können, wo sie gebraucht wird – auch auf ressourcenschonender Low-End-Hardware. Wir forschen an Methoden, um anspruchsvolle KI-Modelle auf solchen „Low-Profile“-Umgebungen hocheffizient zu betreiben. Dies maximiert nicht nur Ihre Unabhängigkeit, sondern ermöglicht auch völlig neue Anwendungsfälle direkt am Ort des Geschehens.
Diese drei Säulen – eine revolutionäre Architektur, souveräne Datengenerierung und die Möglichkeit für präzises & effizientes Finetuning – sind mehr als nur eine Sammlung von Einzel-Bausteinen: sie fügen sich zu einer nahtlosen Wertschöpfungskette für die künftige Skalierung von KI zusammen. Der volle Zugriff auf diese strategischen Werkzeuge versetzt uns in die Lage, aus eigener Kraft heraus KI-Systeme zu entwickeln, die nicht nur leistungsstark, sondern von Grund auf transparent, sicher und auf Ihre Bedürfnisse zugeschnitten sind — ohne jeglichen technologischen Abhängigkeiten von Dritten. In geopolitisch bewegten Zeiten ein wichtiger Aspekt der Eigenständigkeit.
Um unsere Mission weiter voranzutreiben, arbeiten wir gezielt an der Optimierung der zentralen Stellschrauben. Damit verschieben wir die Grenzen des Machbaren, ohne dabei die Sicherheit und Zuverlässigkeit aus den Augen zu verlieren. Bei unserer Tochtergesellschaft ACSL betreiben wir Grundlagenforschung, um die heutigen modellzentrierten KI-Architekturen zu architektonisch fundierten ‚Denkenden Maschinen‘ weiterzuentwickeln. Dies basiert auf unserer innovativen Leibniz-von-Neumann-Architektur – einem spezifischen Entwurf für Verbundsystemstrukturen, der die Stärken der Sprachmodell-Technologie aufgreift und zugleich deren strukturelle Grenzen in Bezug auf Sicherheit, Zuverlässigkeit und menschliche Kontrolle überwindet.
Die Leistungsfähigkeit von kognitiver Intelligenz wird u.a. durch die Qualität der hinterlegten Cognitive Schemata bestimmt. Das Ziel der ACSL ist es, diese Schemata kontinuierlich zu verbessern und auch für komplexeste Denk-Pfade nutzbar zu machen. Wir praktizieren experimentelle Forschung, wie wir diese Steigerung der Intelligenz bei gleichzeitiger Beibehaltung von Sicherheit und Kontrolle als durchgängigem Grund-Prinzip erreichen können. Die Ergebnisse werden öffentlich publiziert und für die Nutzbarmachung in der Wirtschaft dokumentiert und aufbereitet.
Die Qualität von Trainings-Daten hat einen maßgeblichen Einfluss auf das Verhalten von KI-Systemen. Statt uns auf externe Quellen zu verlassen, erzeugen wir mit unserer Open-Source-Pipeline SynthIOS unsere eigenen hochqualitativen Trainingsdaten. So stellen wir sicher, dass die hinterlegten Modelle auf der bestmöglichen und relevantesten Wissensbasis operieren und frei von unerwünschten Verzerrungen sind. Wir entwickeln unsere Daten-Pipelines kontinuierlich weiter.
Eine kontrollierbare Architektur verdient eine präzise Sprache. Damit unsere Systeme nicht nur logisch korrekt, sondern auch in Ihrer spezifischen Domäne exzellent kommunizieren, passen wir Open-Weight-Sprachmodelle mit LoRA (Low-Rank Adaptation) an. Außerdem forschen wir an innovativen Methoden, das Kontextfenster signifikant (Faktor x2, x4 oder gar x8) zu erweitern. Damit erweitern wir gezielt die Fähigkeiten von EU AI Act konformen Open-Source Modellen, um diese für den Business-Einsatz verwend- & anpassbar zu machen.
Die Qualität von Trainings-Daten hat einen maßgeblichen Einfluss auf das Verhalten von KI-Systemen. Statt uns auf externe Quellen zu verlassen, erzeugen wir mit unserer Open-Source-Pipeline SynthIOS unsere eigenen hochqualitativen Trainingsdaten. So stellen wir sicher, dass die hinterlegten Modelle auf der bestmöglichen und relevantesten Wissensbasis operieren und frei von unerwünschten Verzerrungen sind. Wir entwickeln unsere Daten-Pipelines kontinuierlich weiter.
Eine kontrollierbare Architektur verdient eine präzise Sprache. Damit unsere Systeme nicht nur logisch korrekt, sondern auch in Ihrer spezifischen Domäne exzellent kommunizieren, passen wir Open-Weight-Sprachmodelle mit LoRA (Low-Rank Adaptation) an. Außerdem forschen wir an innovativen Methoden, das Kontextfenster signifikant (Faktor x2, x4 oder gar x8) zu erweitern. Damit erweitern wir gezielt die Fähigkeiten von EU AI Act konformen Open-Source Modellen, um diese für den Business-Einsatz verwend- & anpassbar zu machen.
Die Qualität von Trainings-Daten hat einen maßgeblichen Einfluss auf das Verhalten von KI-Systemen. Statt uns auf externe Quellen zu verlassen, erzeugen wir mit unserer Open-Source-Pipeline SynthIOS unsere eigenen hochqualitativen Trainingsdaten. So stellen wir sicher, dass die hinterlegten Modelle auf der bestmöglichen und relevantesten Wissensbasis operieren und frei von unerwünschten Verzerrungen sind. Wir entwickeln unsere Daten-Pipelines kontinuierlich weiter.
Unsere Forschungsagenda verfolgt ein klares, strategisches Ziel: wir machen kontrollierbare KI intelligenter, zugänglicher und leistungsfähiger. Indem wir die Denkfähigkeit der Architektur vertiefen, ihre Effizienz auf jeder Hardware maximieren und die Fähigkeiten konformer Open-Source-Modelle gezielt erweitern, gestalten wir aktiv die nächste Generation souveräner KI-Systeme.
So stellen wir sicher, dass unsere Technologie nicht nur heute führend ist, sondern auch morgen die Standards für vertrauenswürdige künstliche Intelligenz setzt.