e2-research#2 bestätigt erneut:
Architektur steigert Reasoning-Leistung, unabhängig von Modellgröße
Die Entwicklungsreihe von e1 über e2-research#1 bis hin zu e2-research#2 bestätigt eindrucksvoll unsere zentrale Hypothese: Intelligenz entsteht nicht allein durch größere Modelle und ressourcenintensives Training – sondern durch bessere Strukturen.
Wir zeigen: allein durch die Optimierung der kognitiven Architektur – ohne jegliche Änderung am zugrunde liegenden Sprachmodell – können substanzielle Leistungsgewinne erzielt werden. Die Art, wie ein System denkt, wird wichtiger als die Größe seines neuronalen Netzes. Daraus erwächst ein bislang kaum genutzter Skalierungsvektor: die gezielte Strukturierung kognitiver Abläufe – unabhängig von der reinen Modellgröße. Anstatt zusätzliche Parameter zu trainieren, optimieren wir den Denkprozess selbst: durch Ablaufsteuerung, Kontextkomposition und kontrollierte Validierung. Das eröffnet neue Perspektiven jenseits der klassischen Skalierungslogik.
Bemerkenswert an dem Ansatz ist nicht nur die gesteigerte Lösungsgenauigkeit, sondern auch der Zugewinn an Kontrolle über den Lösungsweg: Denkprozesse werden nachvollziehbarer, logische und semantische Ableitungen transparenter.
Externe Validierung: unser Ansatz im Spiegel aktueller KI-Sicherheitsforschung
Wie fundamental der Bedarf an kontrollierbaren Denkprozessen ist, unterstreicht eine aktuelle Publikation von führenden Forschern der KI-Sicherheit, darunter Vertreter von OpenAI, Anthropic, Google DeepMind, Meta, Safe Superintelligence Inc. und Thinking Machines.
In ihrem Paper „Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety“ (Juli 2025) analysieren die Autoren das zentrale Problem des sogenannten Chain-of-Thought (CoT) Monitorings. Sie stellen fest, dass die Denkpfade, die moderne Modelle erzeugen, zwar auf den ersten Blick das Verständnis verbessern, jedoch eine „neue und fragile Möglichkeit“ darstellen. Mit zunehmender Modellintelligenz wird es immer schwieriger, „falsch positive“ – also plausibel klingende, aber fehlerhafte – Denkpfade zu erkennen. Das Training der Modelle optimiert oft nur das Endergebnis, nicht aber die Korrektheit der einzelnen Schritte, was dazu führen kann, dass Modelle das plausible Denken quasi nur simulieren.
Die Autoren kommen zu dem Schluss, dass eine rein modell-interne Überwachung an ihre Grenzen stößt und formulieren eine Empfehlung für einen robusteren Lösungsansatz:
„Anstatt zu versuchen, die Argumentation innerhalb des Modells zu überwachen, könnte ein separates Verfahren die Argumentation des Modells in strukturierte, überprüfbare Artefakte extrahieren und diese extern validieren.“
Genau hier setzt unsere Cognitive Control Architektur an. Die Cognitive Control Unit (CCU) folgt exakt jener Systemlogik, die das Paper fordert. Sie extrahiert die „Rohgedanken“ des LLMs in Form von Logik-Artefakten und validiert diese extern anhand von auditierbaren Cognitive Schemata und Axiomen.
Für eine detaillierte Beschreibung der Architektur verweisen wir auf unser Positions-Paper: „Cognitive Control: eine neue Basis-Architektur für das zuverlässige Denken & Schlussfolgern von KI-Systemen“.
e1 und e2-research#1 haben das Fundament gelegt.
Fortschritte in den Benchmarking-Ergebnissen
Rein logische Puzzles mit hoher Logik-Tiefe (ZebraLogicBench)

Um die reine Logik-Performance zu messen, nutzen wir weiterhin die anspruchsvollen XL-Puzzles des ZebraLogicBench (Erklärung siehe e2-research#1 Announcement). Diese Aufgaben erfordern lange, konsistente Ketten deduktiver Schlussfolgerungen und sind ein idealer Indikator für die Robustheit der logischen Steuerung durch die CCU.
Obwohl die Benchmarks synthetisch sind, spiegeln sie zentrale Anforderungen realer Denkprozesse wider: mehrstufiges, widerspruchsfreies Schlussfolgern mit begrenztem Kontext.
Ergebnisse ZebraLogicBench: Architektonische Skalierung erreicht neue Höhen
Die Ergebnisse bestätigen unsere Hypothese eindrucksvoll. Während e2-research#1 bereits eine starke Performance zeigte, setzt e2-research#2 einen neuen Meilenstein:
- e2-research#2 @ gpt-4.1-mini erzielt eine Lösungsrate von 68,8 % bei den XL-Puzzles,
- diese Verbesserung von über 8 Prozentpunkten gegenüber e2-research#1 wurde erneut ausschließlich durch die Optimierung des Cognitive Schemas erzielt,
- im direkten Vergleich zur Leistung des Basismodells (11 %) bedeutet dies mehr als eine Versechsfachung der Leistungsfähigkeit allein durch die kognitive Architektur.
Damit belegt e2-research#2 aktuell Platz 2 im Ranking und untermauert, dass architektonische Innovation ein nachhaltiger und hocheffizienter Weg zu leistungsfähigerer KI ist.

Multiplikator-Effekt: Architektur + Modelltraining
Bisher haben wir bewusst nur die kognitive Architektur optimiert. Nachdem wir die Wirksamkeit der architektonischen Optimierung isoliert belegt haben, stellt sich nun die nächste strategische Frage: wie stark lässt sich dieser Effekt skalieren, wenn auch das zugrunde liegende Modell gezielt auf deduktives Denken trainiert wird?
Um das Zusammenspiel von Architektur und Modell zu testen, evaluieren wir zusätzlich zwei Varianten eines Llama 3.3-70B – ein untrainiertes Modell, sowie ein von uns feinjustiertes SFT-Modell, welches auf deduktives Denken trainiert wurde.
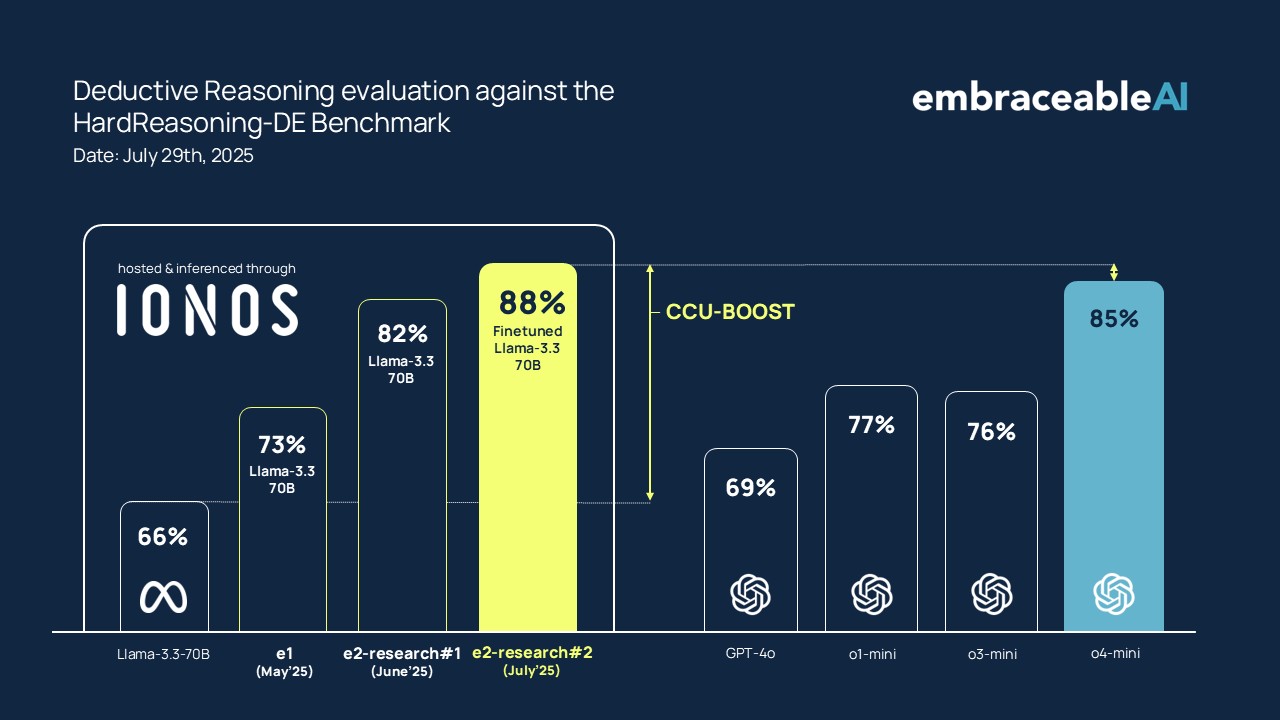
Ergebnisse HardReasoning-DE:
Die weiter verfeinerte Architektur von e2-research#2 zeigt erneut eine deutliche Steigerung der Lösungsgenauigkeit. Die CCU hebt beide Varianten deutlich:
- untrainiertes Llama 3.3-70B: 84,1%
- trainiertes Llama 3.3-70B (SFT): 88,3%
Das SFT-Modell liefert die Fähigkeit, die CCU die Struktur. Im Vergleich mit führenden Reasoning-Modellen positioniert sich unser System mit dem Finetune nun mit 88,3% auf Platz 1 und demonstriert die wachsende Überlegenheit des architektur-zentrierten Ansatzes, insbesondere bei Aufgaben, die mehr als nur die Reproduktion von Trainingsdaten erfordern.
Zusammenfassung und Ausblick
Die Ergebnisse von e2-research#2 sind ein klares Signal: der Weg über die kognitive Architektur ist nicht nur eine Alternative zur Modellskalierung, sondern bietet einen grundlegend neuen Skalierungspfad. Dank der Strukturierungsleistung der CCU können sowohl allgemeine als auch spezialisierte Sprachmodelle ihr volles Potenzial sicher und nachvollziehbar entfalten.
Die Fortschritte von e1 zu e2-research#2 zeigen eine klare Entwicklungslinie auf. Wir verbessern nicht nur die absolute Leistung, sondern vertiefen auch unser Verständnis für das Zusammenspiel von freier Assoziation (LLM) und formaler Kontrolle (CCU).
Wenn sich die Effekte generalisieren lassen, steht ein neues Paradigma bevor: Nicht mehr „größer“, sondern „strukturierter“ wird zur Formel kognitiver Leistungsfähigkeit.
Aus diesen weiteren Erkenntnissen werden wir ableiten können, wie schnell und wie weit die Skalierung trägt.
Referenzen und Quellen
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety: https://arxiv.org/pdf/2507.11473
Hard-Reasoning-DE Benchmark: https://huggingface.co/datasets/embraceableAI/HARD-REASONING-DE
ZebraLogicBench: https://huggingface.co/spaces/allenai/ZebraLogic
ZebraLogic: On the Scaling Limits of LLMs for Logical Reasoning: https://arxiv.org/pdf/2502.01100
ZebraLogic Dataset: https://huggingface.co/datasets/WildEval/ZebraLogic
Zebra-Logic Matrix Complexity: https://github.com/WildEval/ZeroEval/blob/main/zebra_logic_analysis/heatmap_size.png
{kind=link}
