e2-research#2 Confirms:
Architecture Boosts Reasoning Performance, Regardless of Model Size
The development series from e1 to e2-research#1 and now e2-research#2 powerfully reaffirms our core hypothesis: intelligence doesn’t arise solely from larger models and resource-intensive training – it emerges from better structures.
We demonstrate that substantial performance gains can be achieved simply by optimizing the cognitive architecture – without any changes to the underlying language model. How a system thinks becomes more critical than the size of its neural network. This unlocks a largely untapped scaling vector: the targeted structuring of cognitive processes, independent of pure model size. Instead of training additional parameters, we optimize the thinking process itself through process control, context composition, and controlled validation. This opens up new perspectives beyond traditional scaling logic.
Remarkable about this approach is not just the increased solution accuracy, but also the enhanced control over the solution path. Thinking processes become more traceable, and logical and semantic derivations become more transparent.
External Validation: Our Approach Mirrored in Current AI Safety Research
The fundamental need for controllable thinking processes is underscored by a recent publication from leading AI safety researchers, including representatives from OpenAI, Anthropic, Google DeepMind, Meta, Safe Superintelligence Inc., and Thinking Machines.
In their paper, “Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety” (July 2025), the authors analyze the central problem of Chain-of-Thought (CoT) monitoring. They note that while the thought paths generated by modern models initially improve understanding, they represent a “new and fragile opportunity.” As model intelligence increases, it becomes increasingly difficult to identify “false positives” – plausible-sounding but erroneous – thought paths. Model training often optimizes only the final result, not the correctness of individual steps, which can lead models to merely simulate plausible thinking.
The authors conclude that purely model-internal monitoring reaches its limits and recommend a more robust solution:
“That said, process supervision could also make the model reason in safer ways and enable supervision of hard-to-evaluate tasks.”
This is precisely where our Cognitive Control Architecture comes in. The Cognitive Control Unit (CCU) precisely follows the system logic demanded by the paper. It extracts the LLM’s “raw thoughts” in the form of logic artifacts and externally validates them against auditable Cognitive Schemata and Axioms.
For a detailed description of the architecture, please refer to our position paper: “Cognitive Control: A New Foundational Architecture for Reliable Thinking & Reasoning in AI Systems.”
e1 and e2-research#1 laid the foundation.
Advances in Benchmarking Results
Pure Logical Puzzles with High Logical Depth (ZebraLogicBench)

To measure pure logical performance, we continue to use the demanding XL-Puzzles from ZebraLogicBench (explanation available in the e2-research#1 Announcement). These tasks require long, consistent chains of deductive reasoning and are an ideal indicator of the robustness of logical control by the CCU.
Although the benchmarks are synthetic, they reflect core requirements of real-world thinking processes: multi-step, contradiction-free reasoning with limited context.
ZebraLogicBench Results: Architectural Scaling Reaches New Heights
The results impressively confirm our hypothesis. While e2-research#1 already showed strong performance, e2-research#2 sets a new milestone:
- e2-research#2 @ gpt-4.1-mini achieves a 68.8% solution rate on XL-Puzzles.
- This improvement of over 8 percentage points compared to e2-research#1 was again achieved solely through the optimization of the Cognitive Schema.
- In direct comparison to the performance of the base model (11%), this represents more than a six-fold increase in performance through cognitive architecture alone.
This places e2-research#2 currently in 2nd place in the ranking, underscoring that architectural innovation is a sustainable and highly efficient path to more powerful AI.

Multiplier Effect: Architecture + Model Training
Until now, we have deliberately optimized only the cognitive architecture. Having isolated and proven the effectiveness of architectural optimization, the next strategic question arises: how strongly can this effect scale if the underlying model is also specifically trained for deductive reasoning?
To test the interplay of architecture and model, we additionally evaluated two variants of a Llama 3.3-70B – an untrained model and an SFT model fine-tuned by us for deductive reasoning.
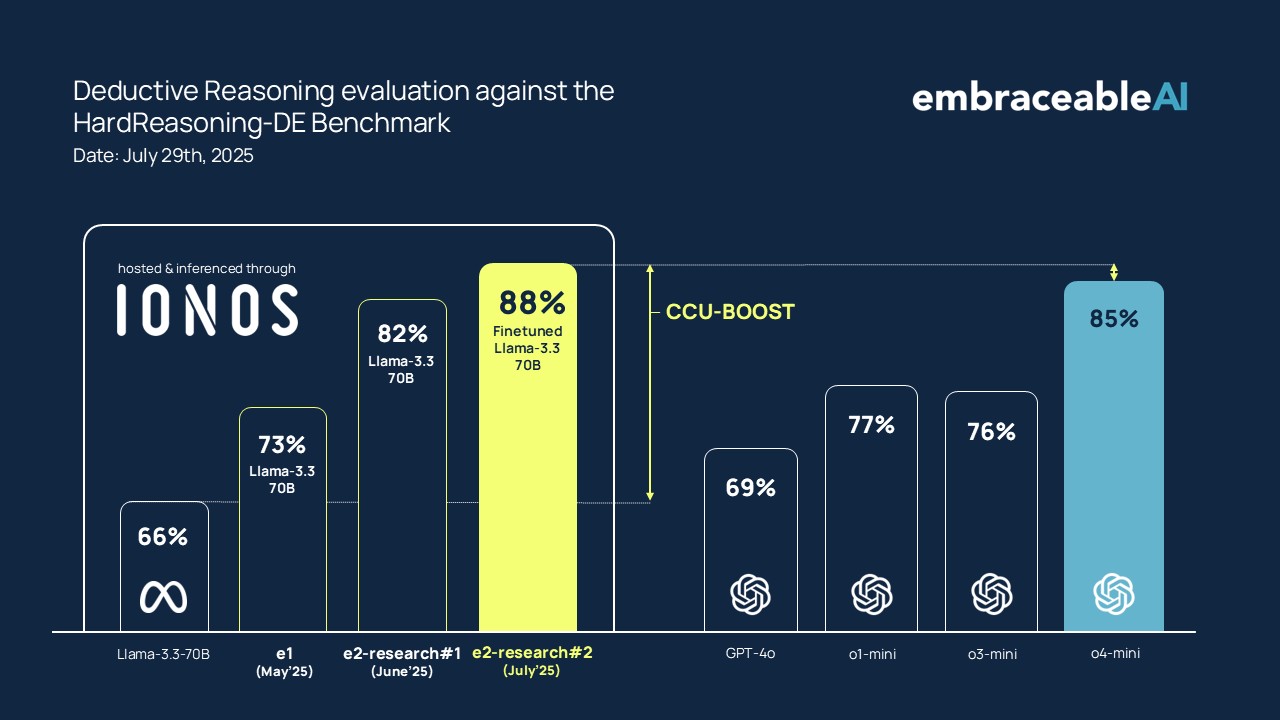
HardReasoning-DE Results:
The further refined e2-research#2 architecture again shows a significant increase in solution accuracy. The CCU clearly elevates both variants:
- Untrained Llama 3.3-70B: 84.1%
- Trained Llama 3.3-70B (SFT): 88.3%
The SFT model provides the capability, the CCU the structure. In comparison with leading reasoning models, our system with the fine-tune now positions itself at 88.3% in 1st place, demonstrating the growing superiority of the architecture-centric approach, especially for tasks that require more than just the reproduction of training data.
Summary and outlook
The results of e2-research#2 are a clear signal: the path via cognitive architecture is not only an alternative to model scaling but offers a fundamentally new scaling path. Thanks to the structuring power of the CCU, both general and specialized language models can safely and traceably unleash their full potential.
The progress from e1 to e2-research#2 shows a clear development trajectory. We are not only improving absolute performance but also deepening our understanding of the interplay between free association (LLM) and formal control (CCU).
If these effects can be generalized, a new paradigm awaits: “more structured” rather than “bigger” will become the formula for cognitive performance.
From these further insights, we will be able to deduce how quickly and how far this scaling will carry.
Referencen und Sources
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety: https://arxiv.org/pdf/2507.11473
Hard-Reasoning-DE Benchmark: https://huggingface.co/datasets/embraceableAI/HARD-REASONING-DE
ZebraLogicBench: https://huggingface.co/spaces/allenai/ZebraLogic
ZebraLogic: On the Scaling Limits of LLMs for Logical Reasoning: https://arxiv.org/pdf/2502.01100
ZebraLogic Dataset: https://huggingface.co/datasets/WildEval/ZebraLogic
Zebra-Logic Matrix Complexity: https://github.com/WildEval/ZeroEval/blob/main/zebra_logic_analysis/heatmap_size.png
{kind=link}
